Construyendo un Event Storage

En "Eventos como mecanismo de almacenamiento", se analizó desde un punto de vista conceptual, como a partir de una serie de eventos se podía reconstruir el estado de una aplicación. Este capítulo se centra en la implementación de un Event Storage (almacén de datos) y algunos de los problemas que surgen al desarrollarlo.
Notas:
La implementación discutida en este capítulo no pretende ser un Event Storage con la calidad suficiente para ser usada en producción, sino para servir como punto de discusión del cómo construir un Event Storage. Esta implementación, aunque no tiene un alto rendimiento, puede satisfacer las necesidades de un gran porcentaje de aplicaciones que se construyen hoy en día.
Para esta implementación explicativa, construiremos el Event Storage en una tecnología existente, un RDBMS. Esto alivia muchos de los problemas (técnicos) que de otro modo surgirían y que están fuera del alcance de esta discusión, esto es, problemas como los modelos de commit de transacciones o la localidad de datos para el rendimiento de lectura.
Estructura
Un Event Storage básico se puede representar en una base de datos relacional utilizando solo dos tablas.
| Nombre de columna | Tipo de columna |
|---|---|
| AggregateId | Guid |
| Data | Blob |
| Version | Int |
Figura 1. Estructura de la tabla Eventos
La primera tabla representa realmente el registro de eventos (Event Log). Habrá una registro o entrada por cada evento en esta tabla. El evento en sí se almacena en la columna [Data]. El evento se almacena utilizando alguna forma de serialización; durante el resto de esta discusión, se asumirá que el mecanismo usa algún tipo de serialización, aunque el uso del patrón Memento puede traer muchas ventajas.
La tabla que se muestra tiene la mínima cantidad de información posible, sin embargo, la mayoría de organizaciones agregan otras columnas, como el tiempo en que se realizó el cambio o alguna información sobre el contexto. Ejemplos de información del contexto pueden ser el usuario que inició el cambio, su dirección IP o el nivel de permiso que tenia cuando sucedio el cambio.
Un número de versión también se almacena junto a cada evento. En la mayoría de los casos, se puede considerarla como un número entero y incremental. El número de versión es único y secuencial solamente dentro del contexto de un Agregado dado. Esto se debe a que la Raíz Agregada (Aggregate Root) define los límites de consistencia (boundaries).
La columna [AggregateId] es una clave externa que se debe indexar; además apunta a la siguiente tabla, que es la tabla de Agregados.
| Nombre de columna | Tipo de columna |
|---|---|
| AggregateId | Guid |
| Type | Varchar |
| Version | Int |
Figura 2. Estructura de la tabla Agregados
Comentario del autor: He dado varias vueltas 😵 sobre si llamar a este concepto "Agregado" (Aggregate) en lugar de otro nombre como "Proveedor de eventos" (Event Provider), ya que realmente Agreggate es un concepto del dominio, sin embargo un Event Storage puede funcionar sin un dominio.
La tabla de Agregados representa los Agregados actuales en el sistema, cada agregado debe tener una registro en esta tabla. Opcionalmente, junto con el identificador podremos tener el número de versión actual desnormalizada para cada Agregado, principalmente por motivos de optimización, ya que podría derivarse de la tabla de Eventos, pero es mucho más rápido consultar la desnormalización en vez de consultarlo directamente la tabla de Eventos. Además, este valor también se utiliza en la verificación de concurrencia optimista ((optimistic concurrency)[https://www.martinfowler.com/eaaCatalog/optimisticOfflineLock.html]).
También se incluye una columna [Tipo] para este ejemplo, este sería el nombre completo del tipo de agregado que se almacena (por ejemplo un Agregado podría ser los Pedidos 120 y 203, mientras que el Tipo de ellos vendría ser Pedido). Esto puede ser útil para varios propósitos, uno de los cuales es en el debug, sin embargo, no es necesario para la creación de un Event Storage básico.
Operaciones
Los Event Storage son mucho más simples que la mayoría de los mecanismos de almacenamiento de datos, ya que no admiten consultas de propósito general. Un Event Storage, en su nivel más simple, tiene solo dos operaciones. Al tener solo dos operaciones hace que un Event Storage sea más simple que la mayoría de los mecanismos de almacenamiento de datos, así como más fácil de optimizar.
La primera operación es obtener todos los eventos de un Agregado. Es extremadamente importante que los eventos se ordenen en el mismo orden en que se escribieron, el número de versión se puede usar para este propósito. Todo esto se puede hacer simplemente usando un RDBMS.
SELECT * FROM events WHERE AggregateID = '' ORDER BY versionEsta es la única consulta que siempre se ejecutará al Event Storage. Otra posible consulta, que puede ser útil, es limitar el conjunto de resultados por una fecha para ver el estado de un Agregado en un momento determinado, pero generalmente un sistema de producción no debería hacer eso.
La otra operación que debe tener un Event Storage es la escritura de un conjunto de eventos en Agregado. Esto se puede hacer bien en código o en un procedimiento almacenado. Es preferido usar un procedimiento almacenado o un SQL generado dinámicamente con sentencias if/for, ya que sino el proceso de inserción tendrá hacer varios viajes de ida y vuelta 🛫. El pseudocódigo para el proceso de inserción se puede ver en el Listado 1.
Begin
version = SELECT version from aggregates where AggregateID = ''
if version is null
insert into aggregates
version = 0
end
if expectedversion != version -- optimistic concurrency test
raise concurrency problem
end
foreach event
insert event with incremented version number
end
update aggregate with last version number
End TransactionListado 1. Operación de escritura en un Event Storage
La operación de escritura también es relativamente simple, aunque hay algunas sutilezas se pueden ver. Primero se verifica si existe un agregado con el identificador único, si no existe, lo crea tomando la versión actual como cero. Luego, se realiza una prueba de concurrencia optimista en los datos que ingresan, si la versión ingresada no coincide con la versión actual, se generará una excepción de concurrencia. Si son iguales, recorrerá los eventos a guardar y los insertará en la tabla de eventos, incrementando el número de versión en uno para cada evento. Finalmente, actualizará la tabla de Agregados al nuevo número de versión actual. Es importante tener en cuenta que estas operaciones están dentro de una transacción, ello es necesario para asegurar que la concurrencia optimista, entre otras cosas, funcione en un entorno distribuido.
El contrato para un Event Storage en código se puede definir con la siguiente interfaz.
public interface EventStore {
void SaveChanges(GUid AggregateId, int OriginatingVersion, IEnumerable<Event> events);
IEnumerable<Event> GetEventsFor(Guid AggregateId);
}Listado 2. Interface para un Event Store
Aunque no es un ejercicio trivial crear un Event Storage de calidad, los conceptos generales detrás de un Event Storage son relativamente fáciles. Probablemente en el futuro habrá muchos sistemas de Event Storage disponibles bien como productos o como proyectos de código abierto (nota, el post original fue escrito en el 2010). Sin embargo, hay una optimización muy importante que se discutió en "Eventos como un mecanismo de almacenamiento" que realmente debería existir en la mayoría de los sistemas y ese es el concepto de una "Rolling Snapshots".
Rolling Snapshots
Las "instantáneas progresivas" (Rolling Snapshots o simplemente Snapshots) son una heurística para evitar la necesidad de cargar todos los eventos de un Agregado. Son una desnormalización del Agregado en un momento dado en el tiempo. Un cambio en la lógica de consulta y una tabla adicional son todo lo que se necesita para agregar esta heurística al Event Storage. Puede encontrar más información sobre Rolling Snapshots a nivel conceptual en el capítulo "Eventos como mecanismo de almacenamiento".
| Nombre de columna | Tipo de columna |
|---|---|
| AggregateId | Guid |
| SerializedData | Blob |
| Version | Int |
Figura 3. Estructura de la tabla Snapshots
La tabla de instantáneas es relativamente básica. Son los datos primarios en el blob que contiene la versión serializada del agregado en un momento dado en el tiempo. Los datos serializados podrían estar en cualquiera de una gran cantidad de esquemas posibles, binarios, XML, texto sin formato, etc. La decisión sobre cómo serializar las instantáneas realmente depende del sistema que se está construyendo. Se incluye un número de versión con la instantánea, que representa qué versión del agregado representa la instantánea.
Para poder crear instantáneas se debe introducir un proceso que maneje la tarea de crear las instantáneas. Este proceso puede vivir fuera del servidor de aplicaciones como un proceso en segundo plano. Puede haber un solo proceso en ejecución o muchos dependiendo de las necesidades debido al rendimiento. Todas las instantáneas suceden de forma asíncrona. La Figura 4 muestra una arquitectura conceptual con un proceso [SnapShotter] introducido.

Figura 4. Introducción a un SnapShotter
El [SnapShotter] se encuentra detrás del Event Storage y consulta periódicamente los agregados que necesitan tomarse una instantánea porque han pasado el número permitido de eventos. Esta consulta se puede hacer con bastante facilidad en el simple Event Storage discutido al unir la tabla de agregados a la tabla de instantáneas en el identificador de agregados. La diferencia se calcula restando la última versión de instantánea de la versión actual con una cláusula where que solo devolvió los agregados con una diferencia mayor que algún número. Esta consulta devolverá todos los agregados que se creará una instantánea. El snapshotter luego iteraría a través de esta lista de agregados para crear los snapshots (si al usar múltiples snapshotters, el patrón de consumidor competidor funciona bien aquí).
El proceso de crear una instantánea implica que el dominio cargue la versión actual del Agregado y luego tomar una instantánea de la misma. La creación de la instantánea se puede hacer de muchas maneras. Una vez que se ha tomado la instantánea, se guarda de nuevo en la tabla de instantáneas para que las consultas tengan la instantánea disponible.
Muchos usan el paquete de serialización predeterminado disponible con su plataforma con buenos resultados, aunque el patrón Memento es bastante útil cuando se trata de instantáneas. El patrón Memento (o serialización personalizada) aísla mejor el dominio a lo largo del tiempo a medida que cambia la estructura de los objetos del dominio. El serializador predeterminado tiene problemas de versión cuando se lanza la nueva estructura (las instantáneas existentes deben eliminarse y recrearse o actualizarse para que coincida con el nuevo esquema). El uso del patrón Memento permite la creación de versiones separadas del esquema de instantáneas desde el objeto de dominio en sí.
En “Eventos como mecanismo de almacenamiento”, se mostró un mecanismo diferente y más simple para el almacenamiento de instantáneas. Ese sistema tenía las instantáneas en línea en el Registro de eventos, este otro mecanismo, aunque conceptualmente más simple tiene algunos problemas que pueden surgir en un sistema de producción. Los problemas giran en torno a la necesidad de ordenar la instantánea dentro del registro de eventos.
Tenga en cuenta que el Snapshotter se ha dado cuenta de que una raíz agregada debe tener una instantánea tomada. Carga el Agregado y toma la instantánea. Desafortunadamente, mientras hacía esto, uno de los Servidores de aplicaciones realizó un cambio en el mismo Agregado. Como la instantánea depende de la posición en el Registro de eventos, recibirá un error de concurrencia optimista. La respuesta fácil sería simplemente repetir el proceso, pero ¿qué pasaría si fallara nuevamente? El snapshotter en un agregado muy ocupado podría terminar en una situación en la que tendría una probabilidad muy baja de escribir la instantánea con éxito.
Al separar las instantáneas en su propia tabla y asociarlas a una versión del agregado, se soluciona este problema. No es necesario ordenar las instantáneas, la instantánea ni siquiera necesita estar en la última versión, la instantánea que se toma es válida en la versión que se tomó.
Las instantáneas son una heurística que mejorará drásticamente el rendimiento de muchos sistemas, aunque no todos los sistemas necesitan instantáneas. En general, se recomienda manejar el desarrollo sin instantáneas, ya que siempre se puede introducir más tarde como una mejora de rendimiento simple para el sistema.
Event Storage como una cola Se ha discutido previamente que los eventos que salen de un dominio también son un [Modelo de Integración]. Muy a menudo, estos eventos no solo se guardan sino que también se publican en la cola donde se envían de forma asíncrona a los oyentes, ya sea dentro del mismo sistema (el modelo de informe es un buen ejemplo) o a otras aplicaciones. Un problema que existe con muchos sistemas que publican eventos es que requieren una confirmación de dos fases entre cualquier almacenamiento que estén utilizando (Relacional o de otro tipo) y la publicación de sus eventos en la cola.
La razón por la que se necesita la confirmación de dos fases es que puede ocurrir una catástrofe durante el pequeño período de tiempo entre la confirmación de la escritura en el almacenamiento de datos y la confirmación de la escritura en la cola. Si ocurriera una falla durante este período, el mensaje no se publicaría en la cola (o si la otra dirección puede publicarse pero el cambio no se puede guardar). Si cualquiera de los dos casos ocurriera, los oyentes de los eventos no estarían sincronizados con el productor.
La confirmación en dos fases puede ser costosa, pero para los sistemas de baja latencia hay un problema mayor cuando se trata de esta situación. En general, la propia cola es persistente, por lo que el evento se escribe dos veces en el disco en la confirmación de dos fases, una vez en el Event Storage y una vez en la cola persistente. Dado que para la mayoría de los sistemas que tienen escrituras duales no es tan importante, pero si tiene requisitos de baja latencia, puede convertirse en una operación bastante costosa, ya que también forzará las búsquedas en el disco. La Figura 5 ilustra la confirmación en dos fases entre el almacenamiento de datos y una cola de publicación.

Figura 5. Commit de 2 fases con Cola
Algunos intentan solucionar este problema escribiendo solo en una cola y luego, al otro lado de la cola, actualizar el almacenamiento de datos con los cambios representados por los eventos; sin embargo, esto tiene algunos problemas. El mayor problema es que no todos los eventos podrán escribirse en el almacenamiento, se ha introducido una consistencia final y es posible que ocurra un problema de concurrencia optimista en la escritura de los eventos. Tratar este problema en un sistema de producción no es trivial.
Muchas organizaciones hacen lo contrario, usan el Event Storage como una cola. Agregar un número de secuencia a la tabla de Eventos discutida previamente permite el uso del Event Storage como una cola. La Figura 5 ilustra el cambio en el esquema de la tabla de Eventos.
| Nombre de columna | Tipo de columna |
|---|---|
| AggregateId | Guid |
| Data | Blob |
| SequenceNumber | Long |
| Version | Int |
Figura 6. Tabla de Eventos como una Cola
La base de datos aseguraría que los valores del número de secuencia sean únicos e incrementales, esto se puede hacer fácilmente usando un tipo de incremento automático. Debido a que los valores son únicos y el incremento de un proceso secundario puede perseguir la tabla de Eventos, publicando los eventos en otra cola. El proceso de búsqueda simplemente tendría que almacenar el valor del número de secuencia del último evento que había procesado, incluso podría actualizar este valor con un compromiso de dos fases que lleva la actualización y la publicación a la cola en la misma transacción. Este proceso se puede ver en la Figura 7.
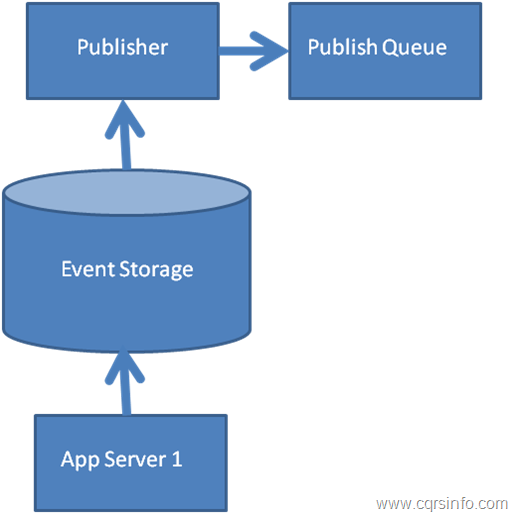
El trabajo se ha retirado del procesamiento inicial de una manera segura conocida. La publicación puede suceder de forma asíncrona a la escritura real. Esto reduce la latencia de completar la operación inicial, también limitará el número de grabaciones de disco en el procesamiento de la solicitud inicial a uno. Esta estrategia puede ser extremadamente valiosa cuando se trata de requisitos de baja latencia ya que permite que gran parte del trabajo en el procesamiento inicial se descargue a otro proceso de forma asíncrona y de manera segura, hay poca diferencia si la publicación se realiza como parte del procesamiento inicial. o de forma asíncrona, ya que, en general, los mensajes se publican de forma asíncrona de todos modos, el uso de Event Store como una cola solo aumenta el tiempo hasta que el mensaje se publica ligeramente, lo que puede verse como un aumento leve del SLA.