Event sourcing: Eventos como un mecanismo de almacenamiento

Una traducción del post Events as Storage Mechanism de Greg Young.
La mayoría de sistemas en producción de hoy dependen de almacenar el estado actual (en estructuras como Persona, Orden, Envio) para procesar las operaciones del día a día. [...]. Sin embargo, no siempre ha sido así.
Antes de la aceptación general de los gestores de bases de datos relacionales (RDBMS) como centro de la arquitectura de un sistema, muchos sistemas no almacenaban el estado actual. En especial esto era verdad, en aquellos sistemas de alto rendimiento, de misiones críticas, y/o sistemas altamente seguros. De hecho si miramos como funciona por dentro una RDBMS veremos que la mayoría de RDMS no trabajan con el estado actual!
La meta de esta sección es introducir el concepto de Event sourcing, mostrarte los beneficios y como un sistema simple de almacenamiento de eventos puede ser creado usando una base de datos relacional.
¿Qué es un evento de dominio?
Un evento es algo que sucedio en el pasado.
Nota: Todos los eventos deben ser representados como verbos en pasado por ejemplo: ClienteReubicado, CargaEnviada, PerdidaInventarioRegistrada. Para los que hablan en francés 🇫🇷, los eventos deben ser en Passé Composé [...].
Los eventos deben tener verbos en pasado ya que forman parte del lenguaje del dominio, el Lenguaje Ubicuo entre desarolladores y expertos del dominio. Considera las diferencias en un Lenguaje ubicuo cuando se hablan de los posibles efectos secundarios (side effects) de reubicar a un cliente, al usar un evento se hace este concepto explícito donde previamente los cambios que ocurrian dentro del Cliente (un Agregado) u otros agregados eran dejados como un concepto implicito que necesitaba ser explorado y definido. Como ejemplo, los side effects solo se podían ver en los ORMs (e.g, Hibernate o Entity Framework), no sabemos que sucede cuando un cliente es reubicado. [...]. La introducción de un evento hace el concepto explicito y parte del Lenguaje Ubicuo; reubicar un cliente no solo produce un cambio X, sino que produce un evento ClienteReubicado el cual es definido explicitamente en el lenguaje.
En términos de código, un evento es simplemente una estructura de almacenamiento de datos, como se puede ver en el Listado 1.
// En C#
public class EventoClienteReubicado {
public readonly Guid IdCliente;
public readonly Location Direccion;
// sin ningún método
public EventoClienteReubicado(Guid id, Location direccion) {
IdCliente = id;
Direccion = direccion
}
}Listado 1. Un evento simple
EL código listado es muy similar al código que puede ser provisto en un Command, un patrón de diseño. Sin embargo, la principal diferencia que existe es en el significado y la intención. Los Command tienen la intención de indicar al sistema que realize una operación, mientras que los eventos son registros de las acciones que sucedieron.
Otras definiciones y discusiones
Hay un concepto relacionado a Evento de Dominio que es definida por SOM(Streamlined Object Modelling). Muchas personas usan el término "Evento de dominio" de SOM:
Modela el evento de personas interactuando en un lugar con una cosa, usando el objeto transacción. Modela una interacción en punto en el tiempo como una transacción con un único timestamp (marca de tiempo); modela una interacción ocurrida en un intervalo de tiempo usando transacciones con múltiples timestamps. Jill Nicola, 2002ll, p. 23
Aunque muchas personas usen SOM para describir Eventos de Dominio, está no es la definición de Evento de Dominio en el contexto de Event Sourcing. SOM usa otra término para el concepto que mejor describe lo que para ellos es, una Transacción. El concepo de un objeto transación es importante en el dominio y absolutamente merece tener un nombre. Un ejemplo de tal transacción podría ser un "jugador balanceando un bate", esto es una acción que ocurrio en un determinado tiempo y que debería ser modelada como tal en el dominio, sin embargo no es lo mismo que un Evento de Dominio.
Además el concepto de Evento de Dominio en Event Sourcing difiere del ejemplo de Martin Fowler.
"Ejemplo: Si voy al restaurante Babur, el Martes, para comprarme una comida, y pago por tarjeta de crédito. Lo podríamos modelar como un evento, cuyo tipo es "Realizar compra", cuyo sujeto es mi tarjeta de crédito, y donde la fecha en la que sucedio sea Martes". - Martin Fowler
Más adelante dice...
"Al canalizar las entradas de un sistema en flujos (streams) de Eventos de Dominio podemos mantener un registro de todas las entradas a un sistema. Ello ayuda a organizar la lógica de procesamiento, y además a mantener un registro (log) de auditoria del sistema." - Martin Fowler
Un lector astuto puedo darse cuenta que lo que Martin realmente está describiendo es un Command, como fue discutido en UIs basadas en Tareas. Usar "Realizar compra", como parte del lenguaje ubicuo, para indicar que una compra fue realizada, esta mal!. Tiene mejor sentido introducir el evento CompraRealizada. Martin realizó una compra en un lugar, se le cargó a su tarjeta de crédito, y seguramente le gustó su comida 😉. Todo lo que sucedio está en pasado, ello sucedió y no puede ser eliminado o deshecho.
Un ejemplo como el anterior, muestra que este enfoque de usar eventos como comandos tiende a conducir a otro problema cuando se desarrolla un sistema así. El problema es que el dominio (sistema) puede ser responsable de llenar partes del evento. Considera un sistema de ventas, a menudo el dominio (sistema) calcula el impuesto de la venta, así como otros cálculos. Esto conduce a la definición doble o dual del evento, hay un evento que es enviado desde el cliente sin un impuesto de venta y otro que tiene impuesto de venta que es agregado por el dominio, con ello causa tener múltiples definiciones de un evento, como también fuerza a tener atributos mutables (atributos que se modifican). Usar eventos duales puede esquivar este problema (tener un evento para el cliente y otro para el dominio) pero esto es básicamente un modelo de eventos como comandos y aún así existen los mismos problemas linguisticos anteriores.
Otro ejemplo de problemas linguisticos se puede apreciar en condiciones de errores. ¿Como el dominio debería manejar el hecho que un cliente haga algo que no puede hacer? Ello puede suceder por muchas razones, por ejemplo al enviar una tarjeta de crédito que posee un saldo menor al monto de la venta. Linguisticamente la separación de comandos/eventos tiene mucho más sentido en ese caso, ya que un Comando esta escrito en imperativo, "RealizarUnaVenta", mientras que un evento está escrito en pasado "VentaCompletada". Es natural (en el dominio) rechazar a un cliente que intenta "realizar una venta"; mientras que no es para nada natural decir a un cliente que algo que sucedio en el pasado (venta completada) realmente no sucedio (por un error), es super confuso. [...]
Estos son los problemas que llevan a separar los conceptos Comandos y Eventos. Esta separación hace el lenguaje más claro, y sútilmente tienden a conducir a los desarrolladores a tener un mejor entendimiento del contexto al usar el lenguaje del dominio. Tener 2 definiciones (definiciones duales) de un concepto fuerza a los desarrolladores a reconocer y distinguir el contexto, ello puede traducirse en tiempo de incremento para los nuevos desarrolladores de un proyecto y otra cosa más que "recordar" para un miembro del equipo. Cada vez que un miembro del equipo necesita recordarse algo para distinguir el contexto, existe una alta posiblidad de que se pase por alto o se confunda con otro contexto. Ser explicito en el lenguaje y evitar definiciones duales, ayuda a tener las cosas claras tanto para los desarrolladores como para los expertos del dominio, y en sí cualquiera que vaya a consumir la API.
Eventos como un mecánismo de almacenamiento
Cuando la mayoría de personas consideran almacenar un objeto, tienden a pensar en su estructura. Esto es cuando consideran como las "ventas", discutidas arriba, deberían ser almacenadas, piensan en que deberían ser almacenadas como "Venta" que tiene "Lineas de articulos" y quiza con alguna "Información de Entrega". Sin embargo, esto no es la única manera que en la que el problema puede ser conceptualizado, otras soluciones ofrecen diferentes y a menudo interesantes propiedades de arquitectura.
Considera por el momento la creación de un pequeño objeto Pedido (Order) para un sistema web de ventas. La mayoría de los desarrolladores imaginarían algo similar a lo que se representa en la Figura 1. Esta es una visión estructural de lo que un Pedido es. Un pedido tiene n Lineas de articulos (Line Items) y Información de Entrega (Shipping Information). Por su puesto, es una vista super simplificada de lo que un Pedido es, pero se puede ver su foco hacia la estructura de un pedido y sus partes.

Sin embargo, esta no es la única forma de ver esta información. Previamente en el área de discusiones vimos el concepto de una transacción, los desarrolladores tratan con el concepto de transacciones regularmente, ellos pueden ser vistos como una representación de los cambios entre un punto y su punto siguiente. Son regularmente llamados "Deltas". El delta entre dos estados estáticos puede ser siempre definido pero más importante muchas veces son dejados como un concepto implicito, usualmente relegados a frameworks como Hibernate en Java o Entity Framework en el mundo de Microsoft. Estos frameworks guardan el estado original y calculan las diferencias entre el nuevo estado y con ello actualizan el modelo de datos. Al hacer los deltas explicitos puede ser altamente valioso en términos técnicos y más importante en beneficios de negocio.
El uso de tales deltas puede ser visto en muchos modelos de negocio maduros. El ejemplo canónico del uso de deltas es en el campo de la contabilidad. Cuando miramos un libro mayor como el de la Figura 2, cada transacción o delta se registra. A su costado, podemos ver el total desnormalizado de una cuenta. Para calcular este número, el delta actual es aplicado al último balance. Podemos confiar que el último balance conocido este bien, debido que podriamos volver a ejecutarse, en cualquier punto dado las transacciones desde el "principio del tiempo" para verificar la validez de ese valor. Con ello tenemos un registro de auditoría verificable.

Debido a que todas las transacciones o deltas asociados con la cuenta existen, podemos leerlos y con ello verificar el resultado. El "balance actual" en cualquier punto puede ser derivado al mirar el "balance actual" o al ejecutar todos los cambios (deltas) desde el inicio de la cuenta. La segunda propiedad es obviamente valiosa en un dominio como el de contabilidad, los contadores trabajan con dinero y la habilidad de verificar los calculos sean realizados correctamente es extremadamente valioso, era incluso valioso desde antes de las computadoras cuando era común ver a un contador por haber hecho una equivocación de calculo a las 3am cuando deberían haber estado durmiendo en vez de leer los libros de contabilidad 😝.
Sin embargo, hay otras propiedades muy interesantes al usar este mecanismo para representar un estado, por ejemplo, es posible retroceder y mirar que estado se tenia en un cualquier punto de tiempo. Considera, por ejemplo, que el sistema permitia tener una cuenta con balance menor a 0 pero en realidad existe un regla que indica que eso no debe suceder. Es posible y relativamente fácil, ver como una cuenta estaba previamente a procesar una transacción que lo dejara con ese estado invalido, haciendo de esa forma que sea mucho más fácil reproducir lo que a menudo terminan como bugs 🐛 en otras circunstancias.
Sin embargo, estos tipos de beneficios no solo se limitan a dominios basados en transacciones de forma natural. De hecho, todos los dominios son, naturalmente, un dominio basado en transacciones cuando se aplica Domain Driven Design. Al aplicar Domain Driven Design hay un gran énfasis en los comportamientos, que normalmente coinciden con los casos de uso, ya que Domain Driven Design está interesado en cómo los usuarios usan el sistema.
Volviendo al ejemplo de Pedido de la Figura 1, el mismo orden podría representarse en la forma de un modelo transaccional como se muestra en la Figura 3.

Esto se puede aplicar a cualquier tipo de objeto. Al reproducirse a través de los eventos, el objeto puede volver al último estado conocido. Es matemáticamente equivalente almacenar el final de la ecuación o la ecuación que la representa. Hay una representación estructural del objeto, pero existe solo al reproducir las transacciones anteriores para devolver la estructura a su último estado conocido, los datos no se conservan en una estructura, sino como una serie de transacciones. Una posibilidad muy interesante aquí es que, a diferencia de cuando se almacena el estado actual de una manera estructural, no hay acoplamiento entre la representación del estado actual en el dominio y en el almacenamiento, la representación del estado actual en el dominio puede variar sin pensar en el mecanismo de persistencia (evitando migraciones o refactorizaciones de bases de datos).
Es de vital importancia notar el lenguaje en la Figura 3. Todos los verbos están en tiempo pasado. Estos son eventos de dominio. Considere lo que sucedería si el idioma estuviera en tiempo imperativo, "Agregar 2 calcetines ítem", "Crear carrito". ¿Qué sucede si hubo comportamientos asociados con la adición del elemento (como reservarlos en un sistema de inventario a través de una llamada por servicio web), deberían estar estos comportamientos al reconstituir el objeto? ¿Qué pasa si la lógica ha cambiado para que este elemento de tal forma estos elementos no pueden agregarse? Este es uno de los muchos ejemplos en los que se requieren contextos duales entre Comandos y Eventos, hay una diferencia contextual entre volver a un estado determinado e intentar la transición a uno nuevo.
No hay Delete (eliminar)
Una pregunta común que surge es cómo eliminar la información. No es posible saltar previamente a la máquina del tiempo y decir que un evento nunca sucedió (eliminar un evento). Como tal, es necesario modelar un borrado explícitamente como una nueva transacción como se muestra en la Figura 4. Ello trae tambien valor al negocio como se ve en "Valor del negocio del registro de eventos".

Figura 4. Una vista transaccional de un Pedido con Delete
En el stream de eventos de la Figura 4, los dos pares de calcetines se agregaron y luego se quitaron. El estado final es equivalente a no haber agregado los dos pares de calcetines. Sin embargo, los datos no se han eliminado, se han agregado nuevos datos para llevar el objeto al estado como si el primer evento no hubiera ocurrido, este proceso se conoce como una Transacción de Reversión (Reversal Transaction).
Al colocar una Transacción de Reversión en el stream de eventos, no solo el objeto vuelve al estado como si el elemento no se hubiera agregado, sino que tambien se deja un rastro que muestra que el objeto había estado en ese estado en un momento dado en el tiempo.
Además existen otros beneficios arquitectónicos al no borrar datos. El sistema de almacenamiento se convierte en una arquitectura solo aditiva o solo apendice (modo append-only), es bien sabido que las arquitecturas de solo adición se distribuyen mejor que las arquitecturas que soportan actualización de datos porque hay muchos menos bloqueos (lock de transacciones, para preservar la atomicidad de ACID) con los que lidiar.
Rendimiento y Escalabilidad
Como un modelo de solo adición, almacenar eventos es un modelo mucho más fácil de escalar. Sin embargo, hay otros beneficios en términos de rendimiento y escalabilidad, especialmente en comparación con un modelo relacional estereotipado o clásico. Como ejemplo, el almacenamiento de eventos ofrece un mecanismo mucho más simple para optimizar, ya que está limitado a un solo modelo de solo adición. Hay muchos otros beneficios.
Particionamiento
Una optimización de rendimiento muy común en los sistemas actuales es el uso del particionamiento horizontal (horizontal partiotining). Con la partición horizontal, el mismo esquema existirá en muchos lugares y alguna clave dentro de los datos se utilizará para determinar en qué lugares existirán los datos. Por ejemplo podemos poner los clientes de con apellido que empiecen con las letras A-M en un servidor X y todos los otros clientes (N-Z) en otro servidor Y. Algunos últimamente se refieren a ello con el nombre de "Sharding". La idea básica es que podemos mantener el mismo esquema en varios lugares (en el ejemplo servidores X, Y, ..), según la clave de una fila (en el ejemplo apellido).
Un problema al intentar utilizar Particionamiento Horizontal en una base de datos relacional es la necesidad de definir la clave con la que debe operar la partición. Este problema desaparece cuando se usan eventos. Los identificadores de los Agregados son el único punto de partición en el sistema (en la Fig 3, el Id del Pedido). No importa cuántos agregados existan o cómo podrían cambiar sus estructuras, el Id. del Agregado asociado a los eventos es el único punto de partición en el sistema.
Por ello, el Particionamiento Horizontal es un proceso muy sencillo.
Guardar objetos
Cuando se trata de un sistema estereotipado (clásico) que utiliza un almacenamiento relacional, puede ser bastante complejo descubrir qué ha cambiado dentro del Agregado. Como se dijo, se han construido muchas herramientas para ayudar a aliviar el dolor que surge de esta tarea a menudo compleja, pero ¿es la necesidad de una herramienta un signo de un problema mayor?.
La mayoría de los ORM pueden descubrir los cambios que se han producido dentro de un grafo (el grafo que internamente usan, como se menciono antes). Generalmente lo hacen manteniendo dos copias de un grafo dado, la primera en memoria y la segunda que permite que otro código interactúe con ella (y la modifique). Cuando llega el momento de guardar el objeto, se recorre el grafo con el que ha interactuo y en base a la copia del grafo original se determina qué ha cambiado mientras el código estaba utilizando el grafo (algo asi como React trabaja con el Virtual DOM).Luego estos cambios se guardan en la base de datos.
En un sistema que está centrado en Eventos de Dominio, los Agregados son en sí seguimientos de los eventos en cuanto de los cambios de ellos mismos. No hay un proceso complejo para comparar grafos, en lugar de eso, simplemente se pregunta al agregado por sus cambios. La operación para solicitar cambios es mucho más eficiente que tener que averiguar qué ha cambiado.
Cargando objetos
Un problema similar existe al cargar objetos. Considere el trabajo que implica cargar un grafo de objetos de una base de datos relacional estereotipada. Muy a menudo hay muchas consultas que deben ser emitidas para construir el agregado. Para ayudar a minimizar el costo de latencia de estas consultas, muchos ORM han introducido una heurística de Carga Diferida (Lazy Loading), también conocida como Carga Demorada (Delayed Loading), donde un proxy se utiliza en lugar del objeto original. Los datos solo se cargan cuando algún código intenta usar ese objeto en particular.
Usar Lazy Loading es útil porque, con frecuencia, un comportamiento dado solo usa una cierta parte de los datos del Agregado y evita que el desarrollador tenga que explícitamente indicar qué datos están pagando el costo de la carga del agregado. Es esta necesidad de pagar el costo lo que muestra un problema.
Los agregados se consideran como un todo, representados por su Raíz Agregada (Aggregate Root). Conceptualmente, un Agregado se carga y se guarda en su totalidad. Evans, 2001.
Conceptualmente, es mucho más fácil tratar el concepto de un Agregado que se carga y guarda en su totalidad. Más el concepto de Lazy Loading no es trivial cuando se utiliza, especialmente, no es trivial cuando se optimizan los casos de uso. Esta heurística es necesaria porque cargar completamente los Agregados de una base de datos relacional es demasiado lento.
Cuando se trata de eventos como un mecanismo de almacenamiento, las cosas son bastante diferentes. Hay solo una cosa que se almacena, los eventos. Simplemente se cargan y reproducen todos los eventos de un Agregado. Solo habrá una sola consulta en el sistema, por lo tanto no hay necesidad de intentar implementar cosas como Lazy Loading. Claro que esto es malo para las personas que desean crear impresionantes frameworks y, con frecuencia, para administrar cosas como Lazy Loading 😆, pero es muy bueno para los equipos de desarrollo pues ya no necesitan aprender estos frameworks.
Muchos rápidamente dirán que sin embargo requiere más consultas que en un sistema relacional, al almacenar eventos puede haber una gran cantidad de eventos para algunos agregados. Esto puede suceder muy a menudo y existe una solución relativamente simple para el problema...
Usando snapshots para ver el pasado (Rolling Snapshots)
Un Snapshot es una desnormalización del estado actual de un Agregado en un momento dado en el tiempo. Representa el estado en el que se han reproducido todos los eventos hasta ese momento. Rolling Snapshots se utiliza como una heurística para evitar la necesidad de cargar todos los eventos para todo el historial de un agregado. La figura 5 muestra un flujo de eventos típico. Una forma de procesar el flujo de eventos es reproducir los eventos desde el principio hasta que se llega al final del evento.
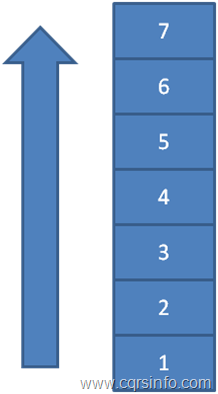 Figura 5. Un Stream de Eventos
Figura 5. Un Stream de Eventos
Sin embargo, puede haber un gran número de eventos desde el inicio hasta el punto actual del sistema, lo cual puede ser un problema. Podemos imaginar fácilmente que hay un stream con un millón o más de eventos que han ocurrido, por lo que tal stream de eventos sería bastante ineficiente de cargar.
La solución es utilizar Snapshots, para guardar el estado en un punto en el tiempo dado (de forma desnormalizada). Entonces con ello, sería posible reproducir solo los eventos desde ese punto en adelante con el fin de cargar el Agregado.
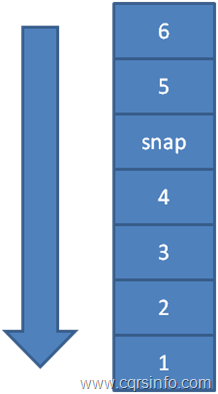
Figura 6. Un stream de Eventos con Snapshot
La Figura 6 muestra una stream de eventos con una Snapshot. El proceso para reconstruir un Agregado cambia cuando se usan Snapshots. En lugar de leer desde el principio del tiempo hacia adelante, se lee hacia atrás colocando los eventos en una pila hasta que no queden más eventos o se encuentre un Snapshot. Luego, el Snapshot se aplica para obtener un Agregado base, y los eventos se remueven de la pila y se aplican hasta que la pila este vacía.
Ten en cuenta que aunque esta es una manera fácil de conceptualizar cómo funcionan los Snapshots, esta no es una solución ideal en un sistema en producción por muchos motivos. Podemos encontrar más información sobre la implementación de Snapshots progresivas en "Creando un Event Storage".
El Snapshot en sí no es más que una forma serializada de un grafo en un punto en el tiempo dado. Al tener el estado de un grafo en un punto en el tiempo, se puede evitar todos los eventos antes a esa Snapshot. Incluso, los Snapshots se pueden tomar de asíncronamente mediante un proceso (en segundo plano) que monitorea el almacén de eventos (Event Store).
Introducir Snapshots permite controlar incluso el peor de los casos cuando se cargan Eventos. El número máximo de eventos que se procesarán se puede ajustar para optimizar el rendimiento del sistema según se necesite. Con la introducción de Snapshots, es un proceso relativamente trivial, lograr uno o dos órdenes de magnitud de mejora en el rendimiento en las operaciones que soporta el Event Store. Sin embargo, es importante recordar que los Snapshots son solo una heurística y que, conceptualmente, el flujo de eventos todavía se puede ver en su totalidad.
Impedance Mismatch
El uso de eventos como un mecanismo de almacenamiento también ofrece propiedades muy diferentes cuando se compara con un modelo relacional típico, cuando se analiza la desigualdad, Impedance Mismatch, que existe entre el modelo tipico relacional y el orientado a objetos. Scott Ambler describe este problema en un ensayo en agiledata.org:
“¿Por qué existe el Impedance Mismatch? El paradigma orientado a objetos se basa en principios probados de ingeniería de software. El paradigma relacional, sin embargo, se basa en principios matemáticos comprobados. Debido a que los paradigmas son distintos, las dos tecnologías no funcionan juntas a la perfección. El impedance mismatch se hace evidente cuando se usa un enfoque: con el paradigma de objetos se accede a otros objetos a través de sus relaciones, mientras que con el paradigma relacional se deben unir (usando joins) filas de datos de las tablas. Esta diferencia fundamental da como resultado una combinación no ideal entre estas 2 tecnologías, aunque.. ¿alguna vez han usado juntas, dos cosas diferentes sin ningún problema? " Scott Ambler
Ello trae un costo, los desarrolladores necesitan conocer tanto el modelo relacional como el modelo orientado a objetos. Además deben estar familiarizados con las muchas diferencias sutiles entre los dos modelos. Scott identifica ello
"Para tener éxito en el uso de bases de datos relacionales y objetos, es necesario comprender ambos paradigmas y sus diferencias, y luego tomar inteligentes decisiones basadas en ese conocimiento". Scott Ambler
Algunas de estas diferencias sutiles se pueden encontrar en la página "Object-Relational Impedance Mismatch" de Wikipedia, algunas de las principales diferencias son:
Interfaces declarativas vs imperativas: el pensamiento relacional tiende a utilizar los datos como interfaces, no el comportamiento como interfaces. Por lo tanto, tiene una inclinación declarativa en la filosofía de diseño en contraste con la inclinación del comportamiento de OO. (Algunos proponentes del enfoque relacional proponen utilizar triggers, procedimientos almacenados, etc. para comportamientos complejos, pero este no es un punto de vista común).
Estructura vs comportamiento: OO se enfoca principalmente en garantizar que la estructura del sistema sea razonable (mantenible, comprensible, extensible, reutilizable, segura), mientras que los sistemas relacionales se enfocan en qué tipo de comportamiento tiene el sistema (eficiencia, adaptabilidad , tolerancia a fallos, vida, integridad lógica, etc.). [...].
Relaciones entre conjuntos y grafos: la relación entre distintos elementos (objetos o registros) tiende a manejarse de manera diferente en distintos paradigmas. Las relaciones relacionales generalmente se basan en idiomas tomados de la teoría de Conjuntos, mientras que las relaciones entre objetos se inclinan más en idiomas adaptados de la teoría de Grafos (incluyendo árboles). Si bien cada uno puede representar la misma información que el otro, los enfoques que brindan para acceder y administrar la información difieren.
Hay muchas otras diferencias sutiles, como los tipos de datos, la identidad y cómo funcionan las transacciones. El Impedance Mismatch entre el enfoque relacional y objetos puede ser una molestia, y requiere una gran cantidad de conocimiento para tratarlo con eficacia.
Sin embargo, no existe Impedance Mismatch entre eventos y el modelo de dominio. Los eventos son en sí mismos un concepto del dominio, la idea de reproducir eventos para alcanzar un estado determinado es también un concepto de dominio (por ejemplo en contabilidad, siempre vemos cada transaccion y con ello tenemos el monto total de ingresos/egresos). Todo el sistema se define en términos del dominio. Definir todo en términos del dominio no solo reduce la cantidad de conocimiento que los desarrolladores necesitan tener, sino que también limita el número necesario de representaciones del modelo, ya que los eventos están directamente relacionados con el propio modelo de dominio.
Valor de negocio del registro de eventos
Es necesario aclarar que el valor de tener un Registro de Eventos (Event Log) está relacionado directamente con lugares en los que desea usar Diseño dirigido por Dominio (del ingles Domain Driven Design o DDD). Es recomendable usar DDD en aquellos lados donde la empresa necesita o tiene una ventaja competitiva. Aplicar DDD es muy difícil y costoso; sin embargo, una empresa recibirá un alto ROI (Retorno de Inversión) si el dominio es complejo y si por usarlo tiene una ventaja competitiva. Similarmente, usar un Event Log tendrá un alto ROI en un área donde se pueda tener ventaja competetiva pero uno muy negativo en otros lados.
Almacenar solo el estado actual solo permite hacer ciertos tipos de preguntas sobre los datos. Por ejemplo, considera ordenes en el mercado de valores, ellas podrían variar por distintos motivos, un comprador podría cambiar el volumen de compra/venta de una orden, el sistema de valores puede ajustar automáticamente el volumen de una orden, o podría ocurrir una transacción que reduzca el volumen disponible en la orden actual.
Si se plantea una pregunta respecto a la liquidez actual, por ejemplo el precio de un número X de acciones, realmente no importa que cambios se produjeron antes, no importa realmente cómo se obtuvieron los datos, importó lo que es, en un punto determinado en el tiempo. Una gran mayoría de consultas, incluso en el mundo de los negocios, se centran en el qué, que promociones podemos ofrecer a los clientes, cuántos productos hay en el almacén.
Sin embargo, hay otros tipos de consultas que son cada vez más populares en los negocios, se centran en cómo. Muchos ejemplos se pueden ver en la palabra de moda "Business Intelligence". ¿Existe una relación entre las personas que han realizado una acción X y su probabilidad de comprar algún producto Y? Este tipo de preguntas generalmente se enfocan en cómo se originó algo en oposición a lo que se llegó a ser.
Es mejor hacer más ejemplos. En una reunión de planificación de una iteración, un experto del dominio tiene una idea para el equipo de desarrollo de un tienda minorista grande en línea. Él cree que existe una correlación entre las personas que agregaron y luego eliminaron un artículo de su carrito, y su probabilidad a responder a las sugerencias de ese producto al comprarlo en un momento posterior. La característica se agregará en la siguiente iteración.
El primer equipo (hipotéticamente) está utilizando para almacenar el estado el mecanismo típico basado en el estado actual. Planean en esta iteración agregar el seguimiento de los elementos a través de una tabla que registra aquellos productos que han sido eliminados del carrito de compras. Planean que elaborarán el informe para la próxima iteración. Después de la segunda iteración, el negocio recibirá un informe pero solo con la información a la iteración anterior, cuando el equipo recien agrego la funcionalidad de rastrear los elementos que se eliminan de los carritos de compra.
Este es un proceso muy estereotipado, muy común. En algunas organizaciones el informe y el seguimiento pueden publicarse simultáneamente, pero este es un detalle relativamente pequeño. Desde una perspectiva empresarial, los expertos en dominios estarán contentos, hicieron una solicitud del equipo y el equipo pudo cumplir rápidamente con la solicitud, la nueva funcionalidad se ha agregado de una manera rápida y relativamente sencilla. El segundo equipo, sin embargo, tendrá un resultado muy diferente.
El segundo equipo ha estado almacenando eventos; representan su estado actual al construirlo en base a estos eventos. Al igual que el primer equipo, agregan el seguimiento de los elementos eliminados de los carros a través de una tabla de hechos, pero además ejecutan este controlador desde el principio del registro de eventos para rellenar todos los datos desde el momento en que comenzó el negocio. Lanzan el informe en la misma iteración y el informe tiene datos que se remontan a años.
El segundo equipo puede hacer esto porque han logrado almacenar lo que realmente hizo el sistema en oposición al estado actual de los datos. Es posible volver atrás y mirar e interpretar los datos antiguos de formas nuevas e interesantes. Nunca se consideró realizar un seguimiento de qué elementos se eliminaron de los carritos o quizás la cantidad de veces que un usuario elimina elementos de su carrito que considerará importantes. Estos son ejemplos de formas nuevas e interesantes de ver los datos.
Como los eventos representan cada acción que el sistema hizo, cualquier modelo posible que describa que el sistema se puede construir a partir de estos eventos.
Las empresas suelen encontrar nuevas e interesantes formas de ver los datos. No es posible, con ningún nivel de confianza, predecir cómo una empresa querrá ver los datos de hoy en cinco años. La capacidad de la empresa para ver datos de la manera que los quiere en cinco años es totalmente desconocida pero posiblemente con mucho valor; ya se ha dicho que esto debe hacerse en áreas donde la empresa puede generar ventaja competitiva, por lo que es relativamente fácil pensar que la capacidad de analizar los datos de hoy de una manera inesperada podría dar ventaja competitiva a la empresa. ¿Ahora cómo valoras el posible éxito o fracaso de una empresa en base a tu decisión de arquitectura?
¿Cómo justifican los equipos de software mirar su bola mágica para predecir qué necesitará el negocio en cinco o incluso diez años? Muchos intentan usar YAGNI, No lo vas a necesitar, pero YAGNI solo se aplica cuando realmente sabes que no lo necesitarás, ¿cómo el mundo dinámico de los negocios puede querer ver los datos dentro de cinco o diez años?
- ¿Es más caro modelar cada comportamiento (evento) en el sistema? Sí.
- ¿Es más costoso en términos de costo de disco y proceso de pensar, almacenar todos los eventos en el sistema? Sí.
- ¿Valen estos costos el ROI cuando la empresa obtiene una ventaja competitiva de los datos?
Trabajos citados
- Ambler, S. W. (n.d.). The Object Relational Mismatch. De agiledata.org: http://www.agiledata.org/essays/impedanceMismatch.html
- Evans, E. (2001). Domain Driven Design. Addisson Wesley.
- Fowler, M. (n.d.). Domain Event. De EAA Dev: http://martinfowler.com/eeaDev/DomainEvent.html
- Jill Nicola, M. M. (2002ll). Streamlined Object Modelling. Prentice H.
- Object-Relational Impedance Mismatch. (n.d.). De Wikipedia: http://en.wikipedia.org/wiki/Object-relational_impedance_mismatch
- Wikipedia. (n.d.). You ain’t gonna need it. De Wikipedia: http://en.wikipedia.org/wiki/You_ain’t_gonna_need_it