DVC: control de versiones de datos y machine learning

Si haz estado en un proyecto de Machine Learning (ML), muy probablemente empezaste probando con modelos simples (un LinearRegression o un LogisticRegression por allá) quizá daban muy buenos resultados, quizá no...luego de un par de días probando modelos o quiza semanas tienes un modelo inicial, simple pero con buenos resultados (como todo buen data scientist anotas todo resultado) y dado que eres Agile decides mostrarlo al cliente. Tienes tu 1ra versión. Sin embargo, al comenzar una nueva semana, tus compañeros te indican sobre una nueva fuente de datos, una que no habias considerado, que quiza mejorara los resultados, entonces trabajas duro para integrar y limpiar la nueva fuente de datos. Y sí como dijeron tus compañeros, los resultados mejoraron! 🙂 Otra nueva semana empieza y sabes que puedes mejorar más los resultados, decides probar más modelos, el lunes avanzas con un NeuralNetwork, el martes un RandomForest, el miercoles un AdaBoost...pero justo el viernes te indican que hay 5000 nuevos registros que probar (antes solo tenias acceso a 3000 registros, pero como las cosas estan yendo bien, te dan mas datos).
Ahora estarás pensando que tan bien funcionan los modelos que desarrolaste al inicio, quiza con esa nueva data funcionaban bien, ¿que haces, conservas los nuevos modelos (y sus hiperparametros) o los deshechas?. Es más, en la tarde, un nuevo compañero decide usar alguna técnica de selección de caracteristicas, y te indica que porfavor lo pruebes, quizá con eso no sea necesario trabajar con modelos muy pesados 😲. Claro que debes probar si esto es verdad, ¿que haces?
A estas alturas te habŕas dado cuenta que en la mayoría de proyectos de machine learning, siempre hay cambios y mucha experimentación, al igual que cualquier software!. Claro, esto es el trabajo para un control de versiones, al igual que habrás versionado tu código fuente (por ejemplo usando Git), quizá quieras intentar hacer lo mismo usando Git para tus datasets y modelos. ¿Pero deberías versionar tus modelos de ML y sus datasets ahí?, si son tan pesados, te preguntarás ¿entrarán en mi servidor de Git (Github, Gitlab...).
Versionamiento y Machine Learning
Este es uno de los problemas que la IA, en especifico el Machine Learning, ha traido al area de ingenieria de software. ¿como versionamos nuestros modelos y sus datasets?, de tal forma que podamos experimentar modelos, ver que modelos funcionaban con que data y cuales no, y más importante poder reproducir experimentos de dias anteriores, incluso semanas.
Por suerte, estamos viendo la aplicación y el desarrollo de versionamiento en esta área de la IA, al igual que en muchas otras áreas, no solo de IA. Una herramienta que es muy útil para resolver este problema es DVC: data version control.
DVC: data version control
DVC es una herramienta complementaria a Git, es decir usamos Git para versionar nuestro código (como siempre lo hemos hecho!), y DVC para versionar la data y todo modelo de ML (sea de cualquier lenguaje o framework: R, julia,scikit-learn, weka...), es decir DVC es agnostica de lenguaje o framework!
Dado que no queremos guardar nuestra data (que usualmente pesa mucho, de MB, GB a ...) en Github o algún servidor de código, la subimos a algún servidor de almacenamiento en la nube (como Google Storage, Amazon S3 o Azure) o servidor local.
Más importante DVC nos ayuda con hacer el desarrollo de ML reproducible, podremos probar versiones de nuestro modelo de hace semanas! Y analizar métricas de semanas y meses. Como lo hace? Ello lo hace por enlazar código y datos con los modelos producidos.
¿Como lo hace?
Por ejemplo, en la figura de abajo, tenemos nuestro codigo (code) de entrenamiento de un modelo (por ejemplo en python, un train.py), este codigo genera un modelo (en python un pickle, model.pkl). Usualmente versionariamos el train.py en git, como el modelo. Sin embargo, como dijimos, para modelos pesados git sufre 😧 y peor con datasets. DVC simplemente crea un archivo que referencia al modelo (model.pkl.dvc), el cual no pesa practicamente nada, este archivo sirve como nexo (ver figura de abajo)
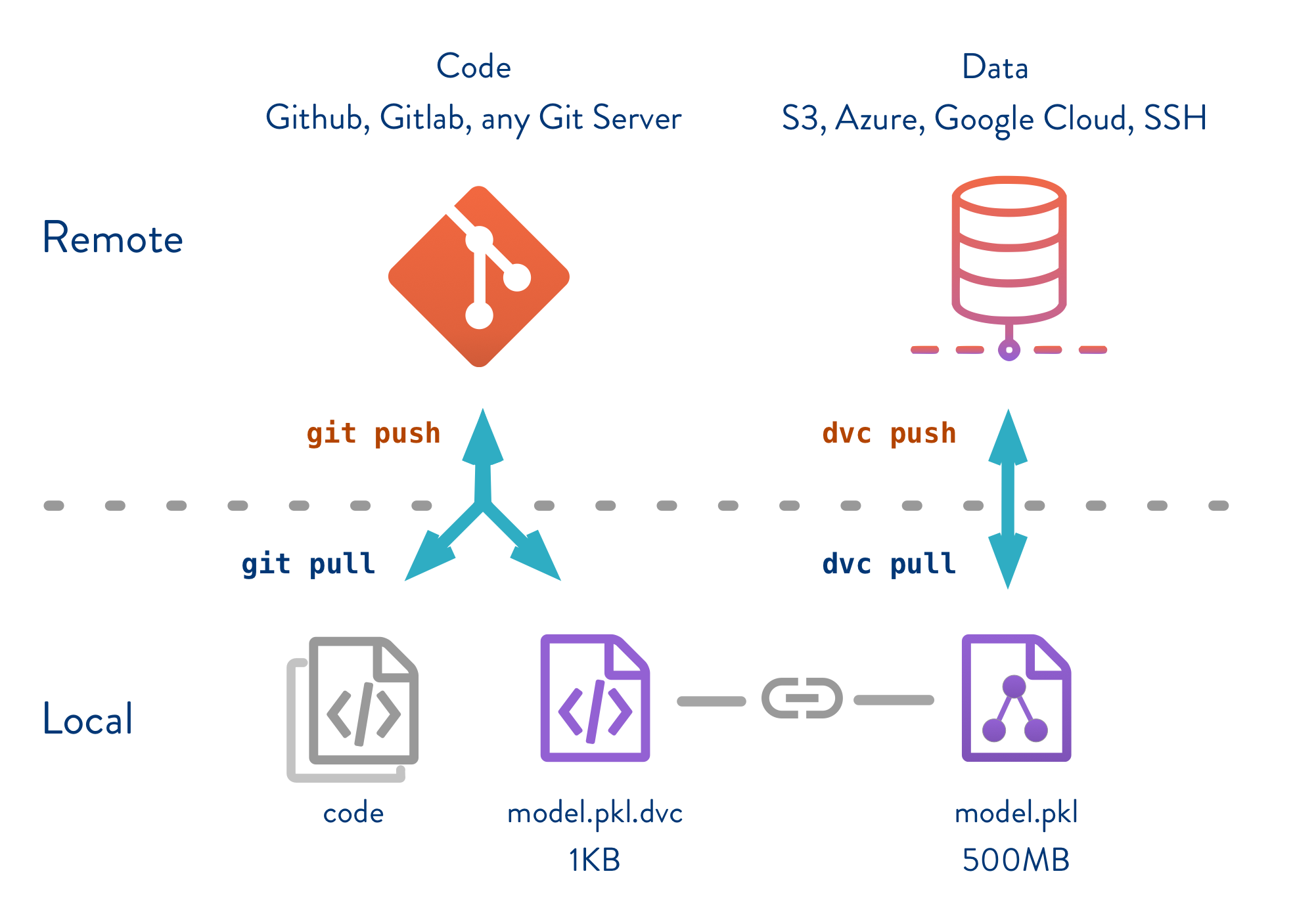
Entonces versionaremos este model.pkl.dvc y train.py en git, mientras dvc se encarga de versionar el model.pkl (que pesa 500mb!). Lo mismo podriamos hacer con datasets. DVC se encargara de versionar nuestros datasets y modelos de la forma más eficiente posible, manteniendo siempre la relación entre el código y el dataset/modelo 😃!
Veamos un ejemplo, para entender como funciona git y dvc juntos 👊
Ejemplo
Primero debes tener instalado dvc, sino instalalo ejecutando pip install dvc (si es que tienes python instalado, puedes ver otras formas de instalarlo aquí).
Imaginare que ya tienes tu proyecto funcionando con git, y simplemente quieres usar dvc, lo único que debes hacer es:
$ dvc init
$ git commit -m "Initialize DVC"Una carpeta .dvc se creara, donde dvc contiene archivos especiales para funcionar, como la carpeta cache.
Y ahora al igual que en git, agregaremos un servidor remoto, como dijimos podemos trabajar con uno propio o de algún servidor cloud:
$ dvc remote add -d myremote /tmp/dvc-storage # en caso de local
$ dvc remote add -d s3remote s3://mybucket/myproject # en caso de amazon s3 - ojo tendrás que instalar la librería dvc[s3], más detalle en su doc.Ahora a todo dataset o modelo de ML, indicaremos que dvc se encargue de gestionarlo:
$ dvc add my-dataset.csvDVC creará ese archivo referencia, que explicamos antes, en este caso my-dataset.csv.dvc (nota el .dvc al final del nombre) y agregara al .gitignore nuestro archivo my-dataset.csv (no queremos que nuestro csv de 50MB lo gestione git). Finalmente, al igual que en git compartiremos nuestro data (en vez de código) a nuestros compañeros, subiendolo al repositorio.
$ dvc pushEllos podran luego bajarse los cambios usando dvc pull.
Existen muchas otras caracteristicas que hacen a DVC especialmente útil, que para mi son las favoritas como reproducir todo un ML pipeline (usando dvc repro) o comparar métricas entre distintas versiones.
Sin embargo, mi tiempo para este articulo se acabo, donde empezar a leer, bueno en su documentación tienen un tutorial y un get-started, donde aprenderás el concepto de pipelines usado por dvc, poder regresar a versiones anteriores y como funciona internamente (aunque una gran parte la explique aquí 😉).
Sin embargo, una de las cosas que me intrigan, es como DVC funciona con bases de datos, aún esta es una herramienta que está documentando como trabajar con BD. Pero... creo que desarrollar una aplicación con Event Sourcing hace una pareja perfecta a Machine Learning, por el hecho de ser en sí un versionador de datos!
Cambios y revisiones:
21/06/2020: fix broken image & improve readability
19/09/2019: add note about event sourcing and ML
18/09/2019: new data version control post